【本站讯】在医疗人工智能领域,各医院和机构出于隐私保护需要,无法直接共享患者数据。联邦学习技术允许多家机构在不交换原始数据的前提下协同训练AI模型,但各机构患者群体的年龄、性别、种族构成差异显著,导致训练出的模型往往对某些群体表现良好,对另一些群体则存在明显诊断偏差。我校计算机科学与技术学院张卫山教授团队针对这一问题,提出了Fair-FedMOE框架,在仅需一轮数据交互的前提下,显著改善了AI模型在不同人群中的诊断公平性。
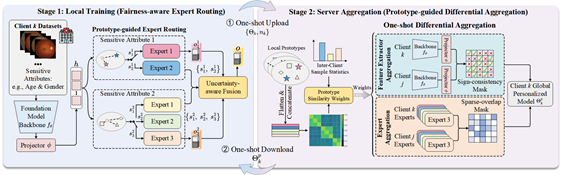
该框架的核心思路是为每类人群建立专属的疾病诊断专家模型。训练时,模型自动学习每类群体的特征,并将对应样本分配给最合适的疾病诊断专家模型处理,从而避免多数群体的数据影响少数群体的学习效果。各机构完成本地训练后,服务器在汇总模型参数时会自动识别并过滤各机构间相互矛盾的更新内容,确保最终模型能够兼顾各类人群。团队还设计了新的公平性评估指标RES-AUC,以表现最差的群体为基准衡量模型整体公平性,避免因群体数量增加导致评估结果失真。在视网膜病变检测、青光眼检测及胸部X射线分析共6个真实医疗数据集上,研究团队分别基于视网膜领域专用基础模型RETFound与通用基础模型DINOv3进行了实验验证,在两种基础模型下Fair-FedMOE均取得最优表现,公平性指标较现有最优方法最高提升8.44%,在18个细分人群交叉的复杂场景下仍保持一致的性能优势。
该工作首次系统研究了一次性联邦学习中的群体公平性问题,阐明了各机构数据分布差异如何导致模型聚合冲突并加剧诊断偏差,在单轮通信约束下同时实现了模型公平性与整体性能的提升,为跨机构协作的公平医疗AI开发提供了新思路。相关成果以“Fair-FedMOE: Group-Fair One-Shot Federated Learning via Prototype-Guided Experts for Medical Imaging Analysis”为题,发表于机器学习领域CCF-A类顶级会议Proceedings of the 43rd International Conference on Machine Learning (ICML 2026)。我校2024级博士研究生孟令钊为第一作者,张卫山教授为通讯作者,中国石油大学(华东)为第一署名单位。该研究获国家自然科学基金及山东省自然科学基金重大基础研究计划等项目资助。




 学习强国号
学习强国号 中国教育发布
中国教育发布 山东教育发布
山东教育发布 石大新浪微博
石大新浪微博 QQ空间
QQ空间 石大官方微信
石大官方微信

